GPT-4o炸裂登场!听说读写如真人
7个月前 (05-14) 21 0
OpenAI在活动中发布了新旗舰模型“GPT-4o”,“可以实时对音频、视觉和文本进行推理。”据介绍,新模型使ChatGPT能够处理50种不同的语言,同时提高了速度和质量。
GPT-4o的“o”代表“omni”。该词意为“全能”,源自拉丁语“omnis”。在英语中“omni”常被用作词根,用来表示“全部”或“所有”的概念。
新闻稿称,GPT-4o是迈向更自然人机交互的一步,它可以接受文本、音频和图像三者组合作为输入,并生成文本、音频和图像的任意组合输出,“与现有模型相比,GPT-4o在图像和音频理解方面尤其出色。”
在GPT-4o之前,用户使用语音模式与ChatGPT对话时,GPT-3.5的平均延迟为2.8秒,GPT-4为5.4秒,音频在输入时还会由于处理方式丢失大量信息,让GPT-4无法直接观察音调、说话的人和背景噪音,也无法输出笑声、歌唱声和表达情感。
与之相比,GPT-4o可以在232毫秒内对音频输入做出反应,与人类在对话中的反应时间相近。在录播视频中,两位高管做出了演示:机器人能够从急促的喘气声中理解“紧张”的含义,并且指导他进行深呼吸,还可以根据用户要求变换语调。

图像输入方面,演示视频显示,OpenAI高管启动摄像头要求实时完成一个一元方程题,ChatGPT轻松完成了任务;另外,高管还展示了ChatGPT桌面版对代码和电脑桌面(一张气温图表)进行实时解读的能力。
OpenAI新闻稿称,“我们跨文本、视觉和音频端到端地训练了一个新模型,这意味着所有输入和输出都由同一神经网络处理。由于GPT-4o是我们第一个结合所有这些模式的模型,因此我们仍然只是浅尝辄止地探索该模型的功能及其局限性。”
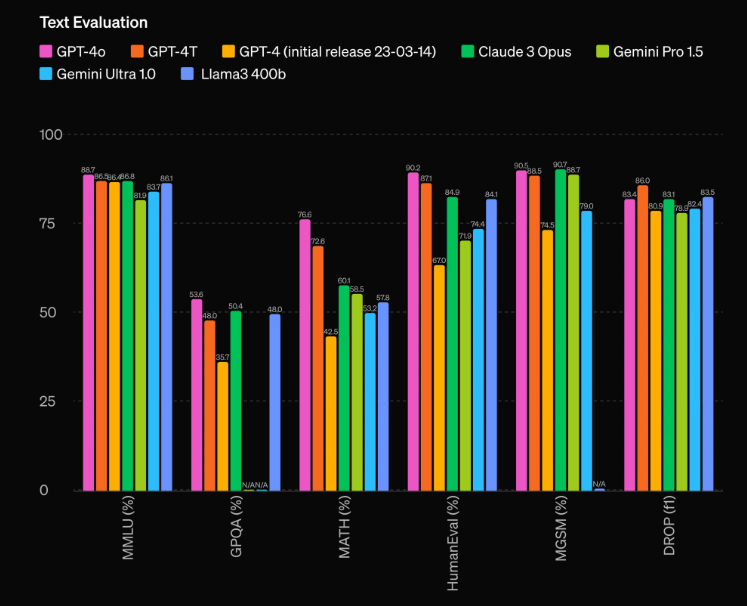
性能方面,根据传统基准测试,GPT-4o在文本、推理和编码等方面实现了与GPT-4 Turbo级别相当的性能,同时在多语言、音频和视觉功能方面的表现分数也创下了新高。
更多工具免费解锁
OpenAI表示,“我们开始向ChatGPT Plus和Team用户推出GPT-4o,并且很快就会向企业用户推出。我们今天还开始推出ChatGPT Free,但有使用限额。 Plus用户的消息限额将比免费用户高出5倍,团队和企业用户的限额会再高一些。”
新闻稿称,即使是ChatGPT Free(免费)用户也可以有机会体验GPT-4o,但当达到限额时,ChatGPT将自动切换到GPT-3.5。
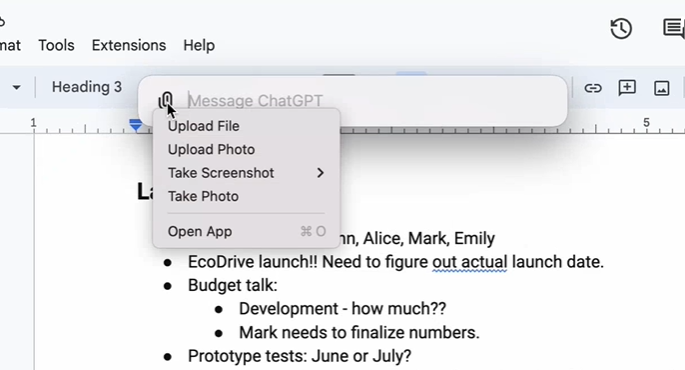
另外,OpenAI还推出适用于macOS的ChatGPT桌面应用程序,通过简单的键盘快捷键(Option + Space)可以立即向ChatGPT提问,还可以直接在应用程序中截取屏幕截图与机器人进行讨论。
在直播活动尾声时,OpenAI首席技术官Mira Murati说道,“感谢杰出的OpenAI团队,也感谢Jensen(黄仁勋)和英伟达团队为我们带来了最先进的GPU,使今天的演示成为可能。”
本文转载自互联网,如有侵权,联系删除






